I’ve been an avid learner of foreign languages my whole life. It’s not just what I do; it’s who I am. Learning English as a girl took me from a small Chinese city to Harvard. While most people consider language learning tedious, I consider it an indulgence, a hobby. I collect words like Pokémon cards, savor them like chocolates.
Recently, I’ve had a few of months of free time thanks to maternity leave, and decided to use this time to take my Japanese to a new level (I’ve been learning Japanese for 10 years). To challenge myself, I signed up for the N1 exam, and started spending hours each day on exam prep.
At the same time, I’ve also been thinking about real-life applications of large language models. I use AI tools like ChatGPT a lot while learning Japanese; it’s fantastic. They are called large “language” models for a reason – they are uniquely positioned to complete language-centric tasks, and language learning is a fantastic use case. Large language models have the potential to turn something tedious and boring into something fun and addictive.
Most educational products on the market are currently leveraging AI as a personal tutor, which is a great use case. But as I was spending hours on intensive Japanese learning, I often imagined use cases that are not yet possible with the current AI products on the market. And below are some of those musings.
Memorizing words is the most painful part of learning a language, but it’s also the most important part. Vocabulary is the building block for languages, the foundation for everything else (like reading, listening, speaking, etc).
Today, most people still memorize words using age-old methods like flashcards, which are based on rote learning and repetition. You try to brute-force the spelling and sounds of new words into your brain. True, these flashcards have progressed from physical paper to apps on smartphones, but the fundamental method hasn’t changed. This method is incredibly boring, and not even that effective. Words must be remembered in context.
For example, one of the words on my vocab list is “寄り添う”, which means “to get close to”. Just by reading the definition in the dictionary, I couldn’t visualize when I would use this word in real life. It’s also kind of abstract and difficult to remember.
Until one day I was watching a Japanese YouTube video where Masayoshi Son was giving his annual SoftBank World keynote address. He was discussing the future of AI, and used the phrase “常に寄り添って” when talking about how personal AI agents will “always be by your side”.
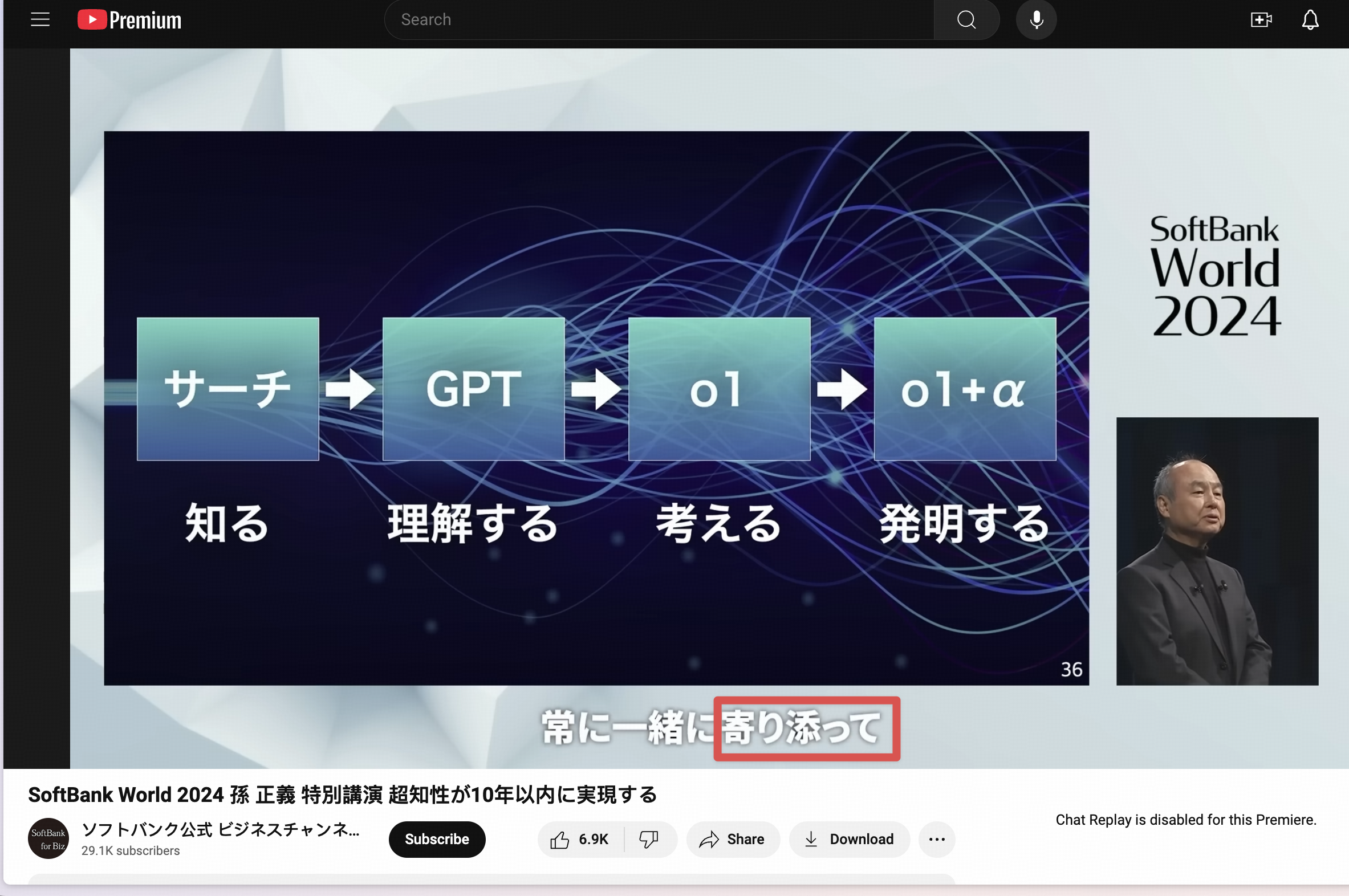
It suddenly clicked for me, and I never forgot this phrase again. Why? Because this unfamiliar word is suddenly connected to a topic I’m interested in and familiar with — AI, technology, the future of agents. It’s like the dots finally connected. It also motivated me to study harder because it showed these words are actually useful. I can definitely see myself saying this phrase to a Japanese person when discussing AI.
But the problem is, it’s extremely difficult and labor-intensive to find the context for all the words that I’m trying to memorize. If I’m preparing for a language exam, I’m usually confronted with a list of 3000 words with their definitions and example sentences. The example sentences help, but they are mostly outdated, boring, and not that memorable.
When I watch Japanese videos or listen to Japanese podcasts, I sometimes come across words on my list, but that totally depends on luck. I get super excited when that happens—this obscure-looking word that I’m trying to learn is used by real Japanese people! I’m not wasting my time! Coming across a memorable line from a TV drama works 10 times better than staring at a textbook for 20 minutes. Can I engineer the above chance encounter for 3000 words, at scale? Is this something that AI can help with?
If I had an all-powerful AI agent, this is the brief I would give them:
Here’s a list of 3000 Japanese words that I need to learn, fast. For every word, go to YouTube and Netflix and find instances of Japanese people actually using this word when talking in videos. Go look at my YouTube and Netflix watch history to get to know the type of content and topics I’m interested in, and make sure the content you find aligns with these interests. Find the sentences where these words appeared in, and cut them into videos that are 10-20 seconds in length. Add accurate bilingual subtitles (Japanese above English) to the videos, and highlight the words that I’m trying to learn. For each words, find 5 videos, since repetition is key. Gather those clips and turn them into a TikTok-like short video feed.
I’m pretty sure I would be addicted to such a video feed, and will master these 3000 words in no time. This is the definition of “edutainment”: the content would be so fun to watch and so educational at the same time. It would make learning almost addictive.
Of course, copyright could be an issue. But we’ll soon get to a level where AI doesn’t even need to find these videos; it can just generate these videos. AI can generate an infinite amount of in-context, modern, engaging conversations that illustrate the correct usage of these words, and curate them into an endless short video feed.
A major reason people struggle to continue learning a language lies in the difficulty of finding the perfect material (like videos, podcasts, articles, books, etc). I consider a piece of material perfect if it meets these two criteria:
- The difficulty level is just right for me, meaning I can understand enough to keep me engaged and motivated, but also learn new expressions. The perfect balance of existing vs new knowledge is probably 7:3 or 8:2
- The subject matter is interesting to me, and related to what I do for work or for fun. It should be the type of content that I would watch out of sheer interest, even if I’m not learning the language
I spend hours scouring the Internet for these types of materials, like videos, podcasts, and dramas. I would love for this work to be outsourced to AI. The AI agent would need to have a perfect understanding of my current level as well as my interests. It would need to have access to data in my dictionary app (to understand my level) as well as my social media feeds and watch history (to understand my interests). Or, like I mentioned above, the AI agent can just generate such content, although the quality would not be that high in the short term.
Conversely, when I’m watching a video and come across a new word that I want to learn, my current workflow is to type out the word in my dictionary app and save it into my vocabulary list. But I only saved the word; I didn’t save the context in which it appeared in. Ideally, I would love to type out the whole sentence where the word appeared in, but that would simply be too much work. Sometimes I would take a screenshot of the subtitles, but my dictionary app doesn’t allow uploading images to attach to words. Imagine if an AI agent could not just save the word for me, but also the whole sentence, along with a link to the exact timestamp of the video where the word appeared, so that when I study the word later, I can easily jump back to revisit the context.
Sometimes we may not need a video; an image would suffice. For me, out of all types of Japanese words, the hardest to memorize are the onomatopoeia. I almost clawed my eye out trying to remember the difference between guzu-guzu and uzu-uzu, jiwa-jiwa and shiwa-shiwa…
But this is where images can really make a difference. A picture is worth a thousand words. Sometimes I would stare at a word’s definition in a dictionary and still don’t understand what it means. Then I would just look the word up in Google Images. And I would suddenly get it.
For example, I asked Perplexity to “Create a list of 100 Japanese onomatopoeia and match them with emojis that can illustrate their meanings.” The resulting list was fantastic. It turns something abstract into something concrete. It’s 10 times more memorable and fun than staring at a boring textbook.

With the ability to generate multi-media content, AI will be able to create images, memes, gifs, tweets, videos, podcasts, short stories… that make languages come to life, and help learners illustrate and memorize words in context.
Another example: I asked ChatGPT to “Make a sentence that contains 信仰, 新興, and 進行”, three words with the exact same pronunciation but very different meanings.

This makes these words much easier to remember, since I can just remember the sentence. Words are better remembered in groups, because our brains love to make associations and linkages. It would be awesome if an AI agent can go to my list of 3000 words, and automatically identify words with similar meanings/pronunciations/roots/structures, and then come up with mnemonics to help me remember them. It’s all about connecting the dots.
In the end, I realized that language learning is just like training myself as a large language model – we just need a shit ton of high-quality data. We need both pre-training, where we expose ourselves to a wide range of real-life Japanese usage examples, as well as post-training, where we fine-tune the way we use the language based on our own contexts and use cases.
The traditional, rule-based way of rote learning doesn’t work. Reading grammar books will not make me fluent in Japanese; moving to Japan will. Short of moving to Japan, I can try to create an artificial environment where I’m exposed to a large amount of high-fidelity data that accurate reflect the way real Japanese people talk today. And AI is perfectly poised to create that environment.

Love it!! I’m super curious where the state of the art for language learning will end up. My guess is something what you’re describing – a combo of immersion and an AI agent working with you to continually feed you areas to improve.
Love that and love your writing, Zara!
老师 我在做一个类似的应用 不过我的思路是日常把刷兴趣视频遇到的生词尽可能生成“现场快照” 包含这些词的所在的句子、视频定位等信息 但是真正想要熟悉一门语言复习是必不可少的 所以这个生词现场快照我还是会放到系统的间隔重复算法里面 随后这个算法会对用户进行测试来筛选出哪些是用户已经掌握哪些,它没有掌握的,剩下的就是把精力放在那些没有掌握的词上,根据间隔重复算法安排的复习时间学习即可
上面的这个思路和很多背单词软件都差不多像是默默背单词。但是我觉得最重要的一天对用户学习进度的量化做得不好。这是一个能够显性体现用户学习进度,提升学习获得感的反馈系统
有时间我会和你分享我的工作进展